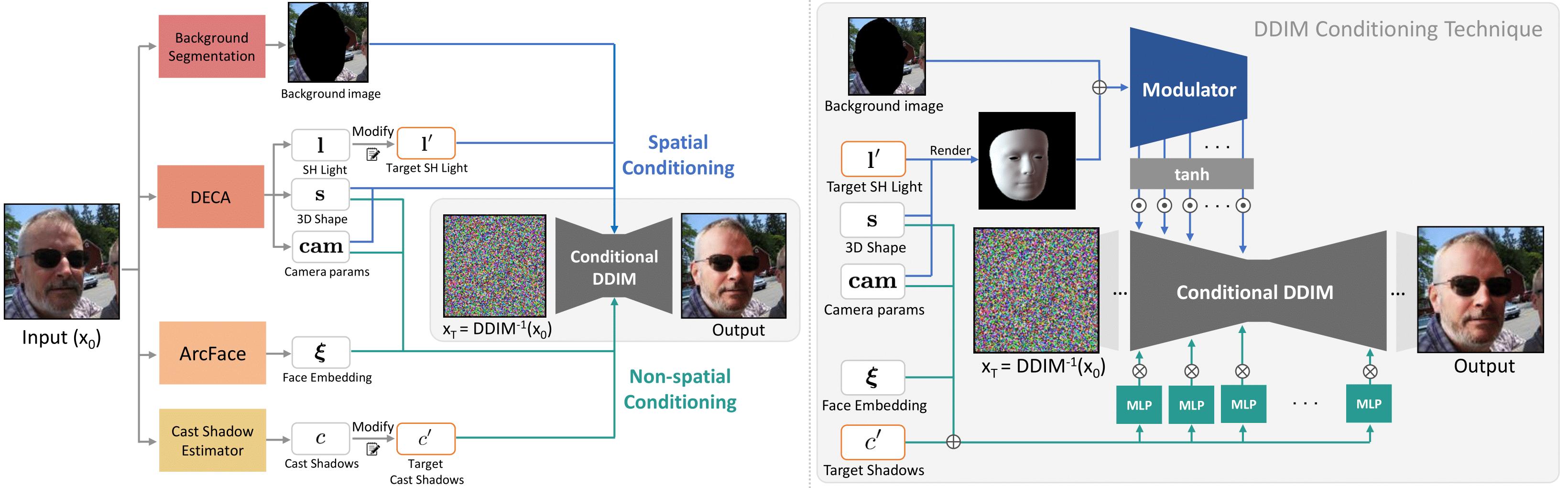
DiFaReli : Diffusion Face Relighting
: Diffusion Face Relighting
VISTEC - Vidyasirimedhi Institute of Science and Technology
Rayong,
Thailand
ICCV 2023

 Code
Code
DiFaReli++ extends
this work DiFaReli
by improving shadow consistency and enabling relighting in a single network pass.
by improving shadow consistency and enabling relighting in a single network pass.